こんにちは!ぼりたそです!
以前、Lasso & Ridge回帰について解説した記事を公開しましたが、「結局どっちを使えばいいの?」、「両方いいとこ取りの手法はないの?」と思いませんでしたか?
その答えが Elastic Net回帰 です。
本記事では、
- Lasso & Ridgeのおさらい
- Elastic Netの数式的な理解
- 3つの回帰の使い分け
- Python実装
まで、体系的に解説します。
また、Lasso & Ridge回帰については過去に解説記事を作成していますので、興味のある方はご参照いただければと思います。
Lasso & Ridge回帰のおさらい
まずは、なぜ正則化が必要なのかを確認しておきましょう。
線形回帰では、予測値は次のように表されます。
$$
\hat{y}_i = x_i^T \beta
$$
ここで、
は説明変数ベクトル、
は回帰係数です。
このとき、回帰モデルの誤差は次のように定義されます。
$$
E(\beta)
=
\sum_{i=1}^{n}
\left(
y_i – x_i^T \beta
\right)^2
$$
これは「予測値と実測値の差(二乗誤差)」をできるだけ小さくする係数 を求める問題です。
一見すると合理的ですが、この方法には弱点があります。
それは、説明変数が多い場合や、説明変数同士に強い相関がある場合、係数が極端に大きくなり、モデルが不安定になることがあるという点です。
この問題を防ぐために導入されるのが 正則化 です。
Lasso回帰(L1正則化)
Lasso回帰では、L1正則化項と呼ばれる係数の絶対値の和をペナルティとして加えます。
$$
E(\beta)
=
\sum_{i=1}^{n}
\left(
y_i – x_i^T \beta
\right)^2
+
\alpha
\sum_{j=1}^{p}
|\beta|
$$
ここで $\alpha$ は正則化の強さを表すパラメータです。
L1正則化項には、係数を0にしやすい性質があります。そのため、Lasso回帰では不要な変数の係数が0になり、自動的に変数選択が行われます。
一方で、説明変数同士の相関が強い場合、Lassoはその中のどれか1つだけを選んでしまうことがあり、モデルが不安定になることがあります。
L1正則化がなぜ変数選択ができるかは回帰係数の空間で考えると直感的に理解しやすいです。
ここでは説明を簡単にするため、説明変数が2つの場合を考えます。
まず、通常の線形回帰の二乗誤差は 等高線 として表すことができ、
- 中心に行くほど誤差が小さい
- 外側に行くほど誤差が大きい
という楕円状の構造になります。
次にL1正則化項は、
$$
|\beta_1| + |\beta_2|
$$
です。
この制約を
$$
|\beta_1| + |\beta_2| \le t
$$
と書くと、係数平面では菱形になります。
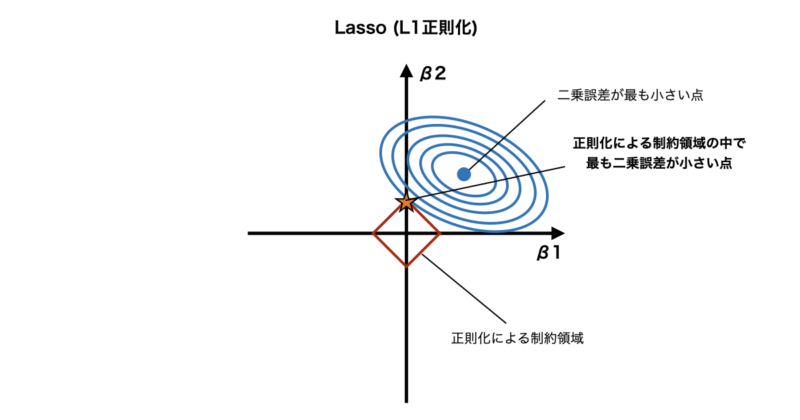
この時、L1正則化の制約を満たしながら最も二乗誤差が小さい係数は楕円と菱形の接点になります。
この接点については図のように菱形の頂点になる場合が多く、図では$\beta_1$が0になることがわかります。
このようにL1正則化を用いるLasso回帰では変数選択が可能となります。
Ridge回帰(L2正則化)
Ridge回帰では、L2正則化項と呼ばれる係数の二乗和をペナルティとして与えます。
$$
E(\beta)
=
\sum_{i=1}^{n}
\left(
y_i – x_i^T \beta
\right)^2
+
\alpha
\sum_{j=1}^{p}
\beta^2
$$
ここで $\alpha$ は正則化の強さを表すパラメータです。
この項を加えることで、係数が大きくなるほどペナルティが増えます。その結果、係数は全体的に小さく抑えられ、モデルの安定性が向上します。
ただし、Ridge回帰では係数が完全に0になることはほとんどありません。そのため、Lassoのように不要な変数を自動的に削除することはできません。
Lasso回帰と同様にRidgeのL2正則化を係数空間で表すと以下のようになります。
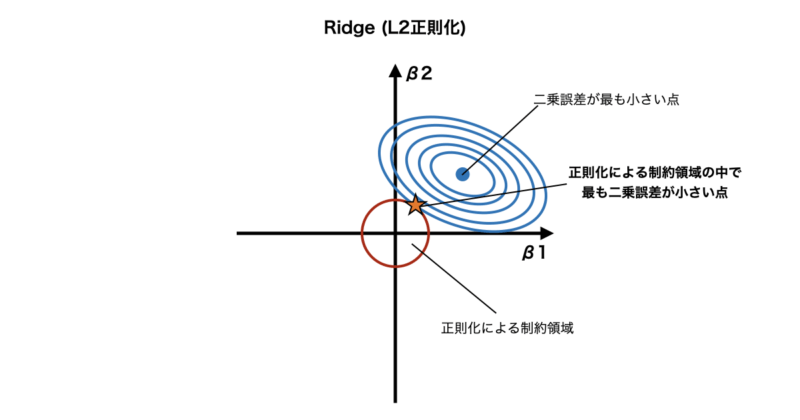
Ridge回帰で使用するL2正則化は次のように表されます。
$$
\beta_1^2 + \beta_2^2
$$
この条件をグラフで表すと
$$
\beta_1^2 + \beta_2^2 \le t
$$
となり、係数平面では 円になります。
最終的な解は楕円と円が最初に接する場所になります。
円は滑らかな形をしているため、係数は 小さくなりますが0にはなりにくいという特徴があります。
このようにL2正則化を用いるRidge回帰では変数の係数が小さくなるが、全ての変数が使われることになります。
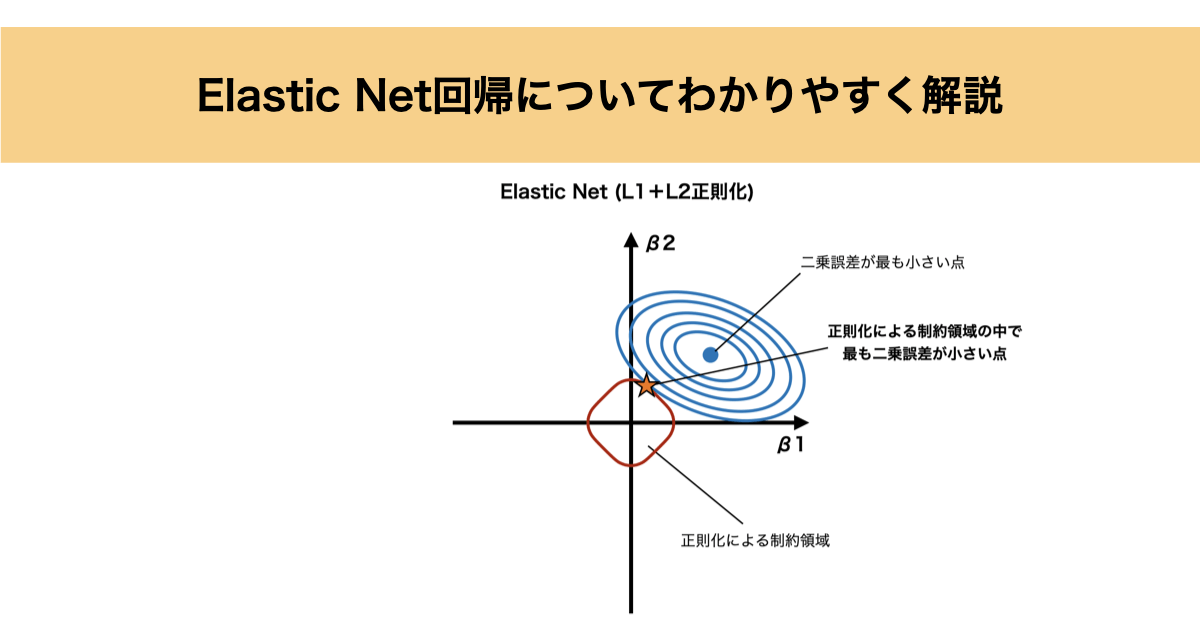
Elastic Net回帰について
Elastic Netは、このL1とL2の両方を組み合わせた正則化です。
損失関数は、次の形で表されます。
$$
E(\beta)
=
\sum_{i=1}^{n}
\left(
y_i – x_i^T \beta
\right)^2
+
\alpha
\left(
\rho
\sum_{j=1}^{p}
|\beta|
+
(1-\rho)
\sum_{j=1}^{p}
\beta^2
\right)
$$
この式をよく見ると、誤差項に加えて、L1とL2の両方が含まれていることがわかります。
ここで、
- :正則化全体の強さ
- :L1の割合
を表します。
が1の場合はLasso回帰と同じになり、が0の場合はRidge回帰になります。つまりElastic Net回帰は、この2つの手法の中間に位置するモデルと言えます。
Elastic Netの大きな特徴は、L1正則化による 変数選択 と、L2正則化による 安定化効果 の両方を同時に得られることです。
そのため、説明変数が多く、かつ説明変数同士に相関がある場合でも、比較的安定したモデルを構築できます。
Elastic Netについても係数空間上で考えると以下のように表すことができます。
Elastic NetはL1正則化とL2正則化を 組み合わせた手法のため、制約の形は円(Ridge)と菱形(Lasso)の 中間のような形になります。
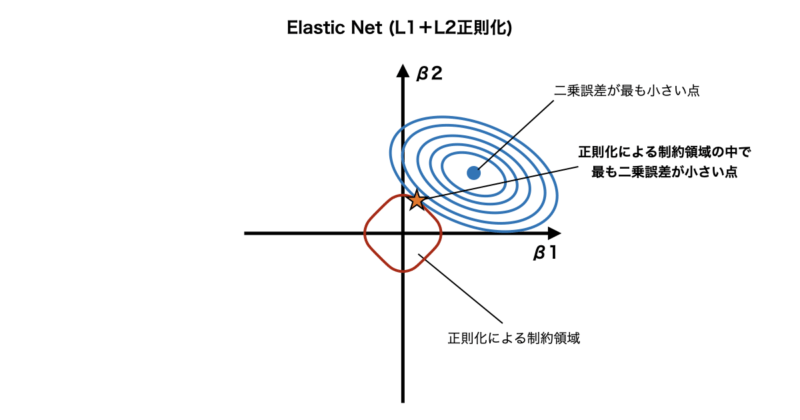
そのため、Elastic Netでは係数を小さくする(L2正則化の効果)かつ不要な係数を0にする(L1正則化の効果)という 両方の特徴を持っています。
Lasso / Ridge / Elastic Netの使い分け
では、実務ではどのように使い分ければよいのでしょうか。
Ridge回帰は、共線性が強く、とにかく安定した予測がほしい場合に向いています。変数は削りたくないが、過学習は防ぎたいというケースが該当します。
Lasso回帰は、重要な変数を絞り込みたい場合や回帰モデルの解釈性を重視する場面では非常に有効と言えます。
Elastic Net回帰は、その両方がほしい場合に使います。共線性があり、かつ変数選択もしたい場合には第一候補になります。
Pythonにおける実装
ここからは、Pythonを使って Lasso・Ridge・Elastic Net の違いを実際に確認してみます。
今回の目的は、高次の多項式回帰によって過学習が起きやすい状況をあえて作り、そのとき各正則化手法がどのように振る舞うかを比較することです。
具体的には、入力 に対して
$$
y = \sin(x)
$$
に従うデータを作成します。学習データにはノイズを加え、より現実的なデータにしています。
また今回は 25次の多項式特徴量を使用します。これほど高次になるとモデルの表現力が非常に高くなるため、通常の線形回帰では訓練データに過剰適合しやすくなります。この状況で Lasso・Ridge・Elastic Net を適用し、正則化によって予測曲線がどのように変化するかを確認します。
なお、これらのモデルは係数にペナルティを与えるため、特徴量のスケールに強く影響されます。特に多項式特徴量では と次数が上がるにつれて値のスケールが大きく変わるため、今回は
- 多項式特徴量の作成
- 標準化
- 回帰モデルの学習
という処理を統一し、すべてのモデルで同じ前処理を適用します。
さらに今回は、予測曲線の比較だけでなく 交差検証(5-fold CV) による汎化性能の評価も行います。各サンプルの予測値を取得し、実測値 vs 予測値の散布図と $R^2$ を用いてモデル性能を確認します。
なお、Elastic NetについてはL1とL2の正則化の割合は1 : 1としてパラメータを設定しています。
実装コードは以下の通りとなります。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures, StandardScaler
from sklearn.linear_model import LinearRegression, Lasso, Ridge, ElasticNet
from sklearn.pipeline import Pipeline
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.model_selection import KFold, cross_val_predict
# ======================
# データ生成
# ======================
np.random.seed(0)
X_train = np.linspace(-3, 3, 50)
y_train = np.sin(X_train) + np.random.normal(0, 0.2, size=X_train.shape)
X_test = np.linspace(-3, 3, 100)
y_test = np.sin(X_test)
X_train = X_train[:, np.newaxis]
X_test = X_test[:, np.newaxis]
poly_degree = 25
# ======================
# 共通前処理
# ======================
def build_model(regressor):
return Pipeline([
("poly", PolynomialFeatures(degree=poly_degree, include_bias=False)),
("scaler", StandardScaler()),
("reg", regressor)
])
# ======================
# モデル定義
# ======================
models = {
"Normal": build_model(LinearRegression()),
"Lasso": build_model(Lasso(alpha=0.01, max_iter=100000)),
"Ridge": build_model(Ridge(alpha=0.1)),
"ElasticNet": build_model(ElasticNet(alpha=0.01, l1_ratio=0.5, max_iter=100000))
}
# ======================
# 学習 + テスト予測
# ======================
predictions_test = {}
mse_scores = {}
for name, model in models.items():
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
predictions_test[name] = y_pred
mse_scores[name] = mean_squared_error(y_test, y_pred)
# ======================
# 予測曲線プロット
# ======================
plt.figure(figsize=(12,8))
plt.plot(X_test, y_test, label="True function", color="green")
for name, y_pred in predictions_test.items():
plt.plot(X_test, y_pred, linestyle="--", label=name)
plt.scatter(X_train, y_train, color="black", label="Training data")
plt.xlabel("X")
plt.ylabel("y")
plt.title("Polynomial Regression Comparison")
plt.legend()
plt.savefig("prediction_comparison.png")
# ======================
# MSE出力
# ======================
print("Test MSE")
for name, mse in mse_scores.items():
print(f"{name}: {mse:.4f}")
# ======================
# Cross Validation
# ======================
cv = KFold(n_splits=5, shuffle=True, random_state=0)
cv_predictions = {}
cv_r2_scores = {}
for name, model in models.items():
y_pred_cv = cross_val_predict(model, X_train, y_train, cv=cv)
cv_predictions[name] = y_pred_cv
cv_r2_scores[name] = r2_score(y_train, y_pred_cv)
print("\nCross Validation R2")
for name, r2 in cv_r2_scores.items():
print(f"{name}: {r2:.3f}")
# ======================
# 実測値 vs 予測値
# ======================
fig, axes = plt.subplots(2,2, figsize=(12,10))
axes = axes.ravel()
for ax, (name, y_pred) in zip(axes, cv_predictions.items()):
ax.scatter(y_train, y_pred)
min_val = min(y_train.min(), y_pred.min())
max_val = max(y_train.max(), y_pred.max())
ax.plot([min_val,max_val],[min_val,max_val], linestyle="--")
ax.set_title(f"{name} (R2={cv_r2_scores[name]:.3f})")
ax.set_xlabel("Observed")
ax.set_ylabel("Predicted")
plt.tight_layout()
plt.savefig("cv_actual_vs_predicted.png")
まずは出力結果のMSEと予測曲線を確認します。
Test MSE
Normal: 0.0349
Lasso: 0.0133
Ridge: 0.0094
ElasticNet: 0.0158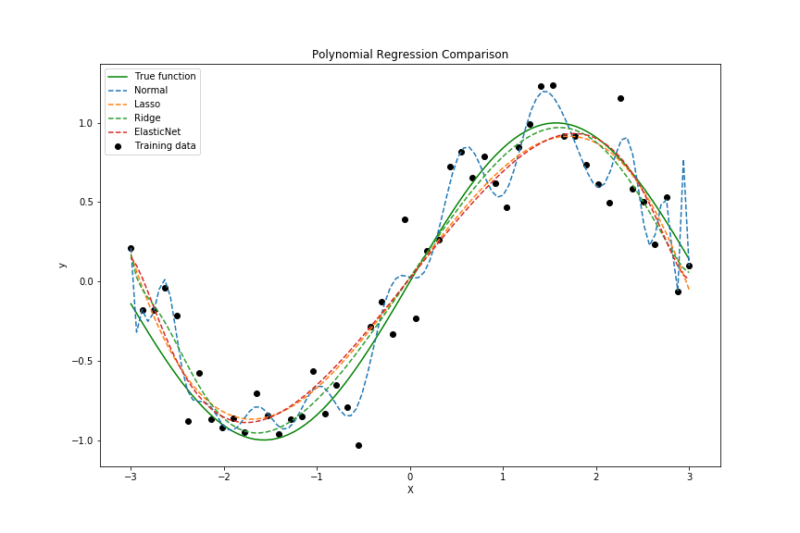
MSEは小さいほど良いモデルです。
今回の結果ではRidge回帰が最も小さい誤差になっていますが、回帰の予測曲線を見ると少し学習データに対して過学習していることがわかります。
なお、通常の線形回帰(Normal)は明らかに過学習していることがわかると思います。
次に各モデルの予測汎化性を評価した5fold CVの $R^2$ を見ていきましょう。
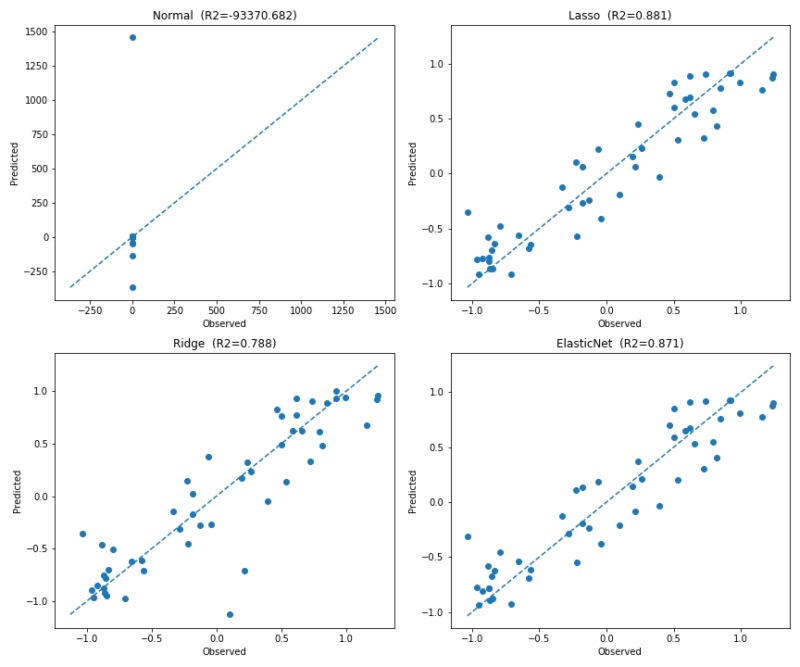
$R^2$ は1に近いほど良いモデルであることを示しますが、0より小さい場合は
平均値で予測するモデルよりも悪いということを意味します。
つまり今回のNormal(通常の線形回帰)モデルは、過学習していて予測モデルとしてほとんど機能していないと言えます。
一方、正則化を取り入れたLasso・Ridge・Elastic Netは予測汎化性が良好でした。
今回の検証データでは、Elastic Net の結果は
$R^2$ = 0.871
となりました。これはLassoとほぼ同程度であり、Ridgeよりも高い値になっています。
Elastic NetはL1、L2両方の正則化を組み合わせた手法です。
そのため、
- L1正則化 → 変数選択(Lassoの特徴)
- L2正則化 → モデルの安定化(Ridgeの特徴)
という両方の効果を同時に得ることができます。
今回のデータでは説明変数が多く(25次多項式)、変数同士の相関も強いため、Elastic NetのようにL1とL2を組み合わせた手法が有効に働いていると考えられます。
まとめ
以上がElastic Net回帰に関する解説になります。Elastic Net は、LassoとRidgeの特徴を組み合わせた手法であり、
- 変数選択
- モデルの安定性
の両方をバランスよく実現できる点が特徴です。
そのため、説明変数が多く相関も強いデータでは、Elastic Net が有力な選択肢になります。回帰モデルを使い分けられるようになることは、実務での大きな武器になるので、ぜひ一度、ご自身のデータで試してみてください。