こんにちは!ぼりたそです!
今回はPythonライブラリであるPHYSBOでベイズ最適化を実行する手法についてご紹介します。
この記事は以下のポイントでまとめています。
- PHYSBOについて
- ベイズ最適化のフロー
- ベイズ最適化の実行コードと解説
それでは詳細に説明していきます。
PHYSBOについて
PHYSBO(optimization tool for PHYSics based on Bayesian Optimization)は、高速でスケーラブルなベイズ最適化のためのPythonライブラリとなっています。
このライブラリは東京大学 物性研究所をはじめとしたチームによって開発されています。
詳しくは以下の公式ドキュメントを参照いただければと思います。
https://issp-center-dev.github.io/PHYSBO/manual/master/ja/introduction.html
一般的なベイズ最適化では計算コストが大きく、scikit-learnなどでベイズ最適化を実行する場合は多くのデータを扱うのは困難であるのに対してPHYSBOは以下の特徴により高いスケーラビリティを実現しているそうです。
- Thompson Sampling
- random feature map
- one-rank Cholesky update
- automatic hyperparameter tuning
ベイズ最適化のフロー
次に今回実装するベイズ最適化のフローについてご説明します。
本記事では以下の関数について最大点を見つけるために最適化を実行していきます。
$$f(x) = \sin(x) \cdot \cos(x) \cdot x^{-1}$$
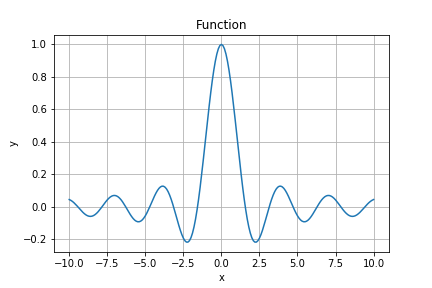
最大値となるのがx=0の時ですが、果たして最適化で導き出せるのでしょうか?というのが今回のお題ですね。
具体的な条件については以下の通りとなります。
| 目標値 | $f(x) = \sin(x) \cdot \cos(x) \cdot x^{-1}$の最大化 |
| 学習データ(初期データ) | x=(-7, -6.5, -6, -5.5, -5, -4.5, -4) |
| 学習モデル | ガウス過程回帰(GP) |
| カーネル | RBF |
| 獲得関数 | EI |
実行コード
それでは実際にベイズ最適化を実行したコードを以下にご紹介します。
以下のコードはPHYSBOのドキュメントにあるチュートリアルを基にしたコードになります。
PHYSBOドキュメント↓↓↓↓
https://issp-center-dev.github.io/PHYSBO/manual/master/ja/index.html
import numpy as np
import scipy
import physbo
import itertools
#探索範囲の定義
window_num=2000
x_max = 10.0
x_min = -10.0
X = np.linspace(x_min,x_max,window_num).reshape(window_num, 1)
#シミュレーターのセット
class simulator:
def __call__(self, action):
action_idx = action[0]
x = X[action_idx][0]
fx = np.sin(x)*np.cos(x)*x**-1
fx_list.append(fx)
x_list.append(X[action_idx][0])
print ("x_opt=", x_list[np.argmax(np.array(fx_list))])
return fx
# policy のセット
policy = physbo.search.discrete.policy(test_X=X)
# シード値のセット
policy.set_seed(90)
#ランダムサーチ
fx_list=[]
x_list = []
res = policy.random_search(max_num_probes=10, simulator=simulator())
#ベイズ最適化の実行
while np.max(fx_list)<0.99:
res = policy.bayes_search(max_num_probes=1, simulator=simulator(), score='EI', interval=0)
mean = policy.get_post_fmean(X)
var = policy.get_post_fcov(X)
std = np.sqrt(var)
#ガウス過程回帰の結果と選択した候補点の描画
x = X[:,0]
fig, ax = plt.subplots()
ax.plot(x, mean)
ax.plot(x_list,fx_list,color='black', marker='o', linestyle='None')
ax.plot(x_list[-1], fx_list[-1], color='r', marker='o')
ax.fill_between(x, (mean-std), (mean+std), color='b', alpha=.1)
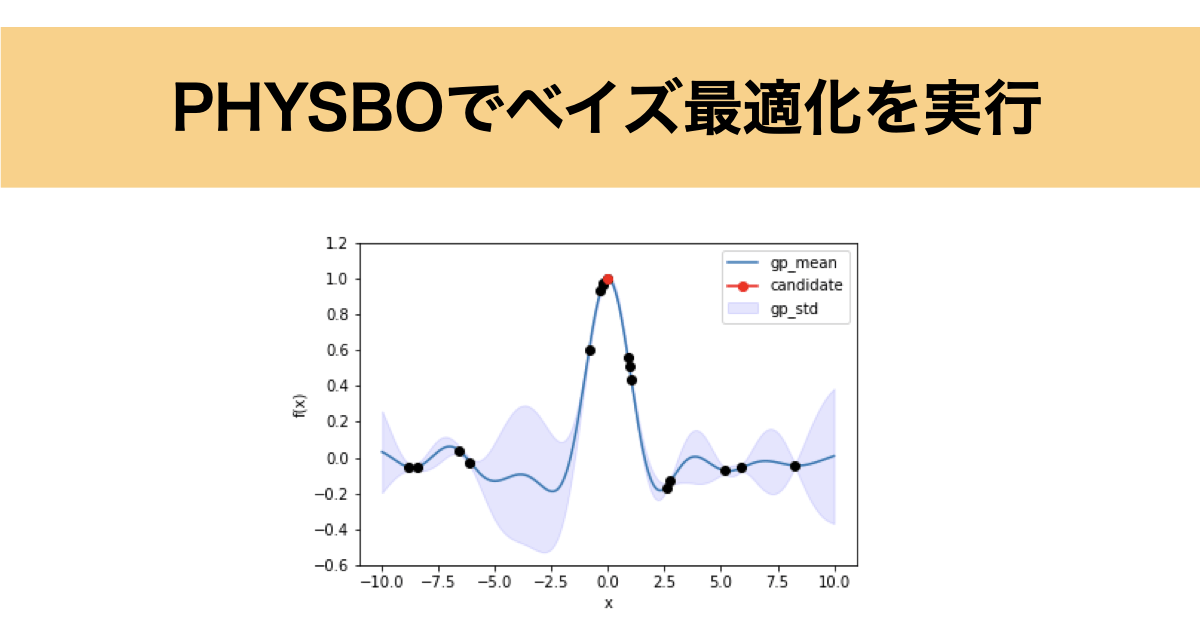
上記のコードを実行した結果、6回目の探索でほぼ最適解に辿り着いています。
下に記載しているのはガウス過程回帰による事後分布とどの点を選択したかを視覚的に表した図になります。
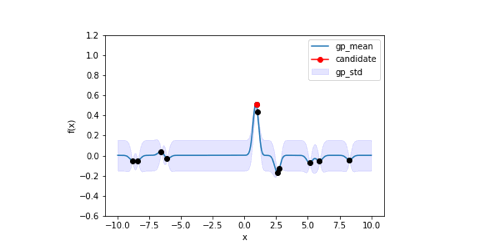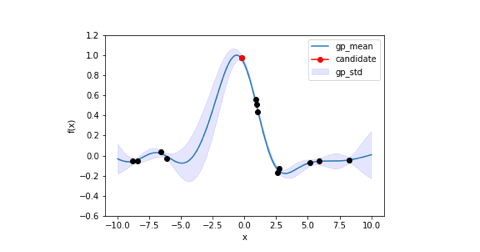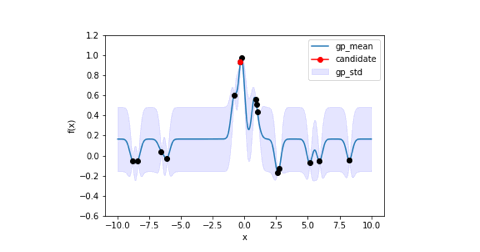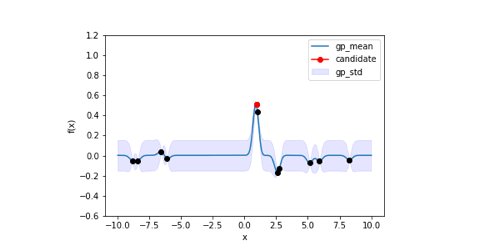
局所解に陥ったりしていますが、最終的には最適解に辿り着いています。また、事後分布の平均線に注目すると設定した目的関数とほぼ同じになっていますね。
コードの解説
それでは今回実行したベイズ最適化のコードについて解説していきます。
手順としては大きく以下の5つになります。
- 探索範囲の定義
- simulatorの設定
- policyの設定
- ランダムサーチ(初期データの用意)
- ベイズ最適化
探索範囲の定義
まずは探索範囲の定義について説明します。
今回の実装コードでは以下の部分で実行しています。
#探索範囲の定義
window_num=2000
x_max = 10.0
x_min = -10.0
X = np.linspace(x_min,x_max,window_num).reshape(window_num, 1)x_max, x_minにそれぞれ探索範囲の上限と下限を設定し、window_numに探索範囲を何分割するかを数値で設定します。
今回は説明変数が一つですが、複数ある場合はその分探索領域を定義する必要があります。
simulatorの設定
次にsimulatorの設定について解説していきます。
simulatorでは目的関数の設定を行なっており、今回のコードでは以下の部分で実行しています。
#シミュレーターのセット
class simulator:
def __call__(self, action):
action_idx = action[0]
x = X[action_idx][0]
fx = np.sin(x)*np.cos(x)*x**-1
fx_list.append(fx)
x_list.append(X[action_idx][0])
print ("x_opt=", x_list[np.argmax(np.array(fx_list))])
return fxsimulatorはクラスであり、まずはcall関数を定義しています。引数はactionであり、これは次の候補点のインデックスが設定されます。
actionから次の候補点のインデックスをaction_idxとして取得し、そのインデックスから次の候補点をxとして取得しています。
その後、関数であるf(x)を計算し、f(x)と候補点xをリストに追加して返り値としてfxを設定します。
policyの設定
次にpolicyの設定について解説していきます。
今回のコードでは以下の部分でpolicyを設定しています。
# policy のセット
policy = physbo.search.discrete.policy(test_X=X)
# シード値のセット
policy.set_seed(90)このコードでは最適化の設定を行なっており、引数test_Xには探索範囲のndarrayを設定します。
ランダムサーチ(初期データの用意)
次に初期データの用意として実行するランダムサーチについて解説します。
今回のコードでは以下の部分で実行しています。
#ランダムサーチ
fx_list=[]
x_list = []
res = policy.random_search(max_num_probes=10, simulator=simulator())このコードでは先ほど設定したpolicyから探索範囲の中でランダムサーチにより探索を行うコードとなっています。
引数としてmax_num_probesには何回探索を行うかを設定し、simulatorには自分で定義したsimulatorを設定します。
ベイズ最適化
次にベイズ最適化について解説していきます。
今回のコードでは以下の部分で実行しています。
#ベイズ最適化の実行
while np.max(fx_list)<0.99:
res = policy.bayes_search(max_num_probes=1, simulator=simulator(), score='EI', interval=0)このコードでもpolicyからベイズ最適化の条件を設定しています。
引数の種類と設定値は以下の通りです。
| 引数 | 設定値 |
| max_num_probes | 一度に行う探索数 |
| simulator | 定義したsimulatorクラス |
| score | 獲得関数(TS,EI,PIから選択) |
| interval | ハイパーパラメータの学習を行う間隔。 0にした場合は最初の一回のみ学習する。 |
終わりに
以上がPHYSBOでベイズ最適化を行う手法についての解説になります。非常に少ないコードで実行できるので扱いやすいですし、ドキュメントも充実しているので、わからない箇所もすぐに調べられるのがいいですね。
GPyOptというライブラリでもベイズ最適化の実行方法についてまとめているので、興味がある方は以下よりご参照ください