こんにちは!ぼりたそです!
今回はPythonでCSVを入力するだけでランダムフォレスト回帰が実行できるコードを作成したので、ご紹介したいと思います。
この記事は以下のポイントでまとめています。
- ランダムフォレストとは?
- 実装コードの仕組み
- 実装コードと解説
- オススメの書籍
それでは、順番に解説していきます。
ランダムフォレスト回帰とは?
まずはランダムフォレストとは何か?ということについてご紹介します。
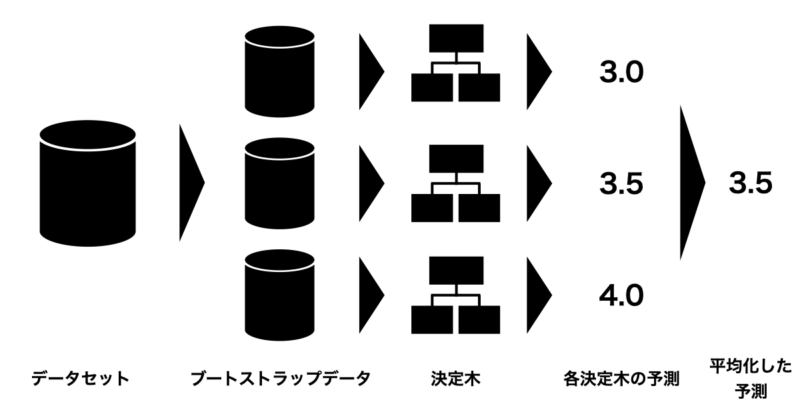
ランダムフォレスととは、アンサンブル学習の一つで複数の決定木を構築して、各決定木の推定値の平均値(多数決)から予測する手法となります。
下の図にランダムフォレストの概略図を示しておりますが、まずデータセットから複数のデータセットに分割します(ブートストラップデータ)。
このデータから複数の決定木を構築し、各決定木ごとに推定値を算出します。その推定値の平均値(または多数決)から予測するという流れですね。
詳細は以下の記事にまとめてありますので、ご参照いただければと思います。

実装コードの仕組み
次に実装コードの仕組みについて説明します。
今回のコードは学習データが格納されたCSVファイルを入力することでランダムフォレスト回帰を実行し、結果をCSVファイルとして出力するようになっています。
入力ファイルと出力ファイルは以下の詳細は以下の通りです。
■入力ファイル
- 学習データ(CSVファイル)
一列目に目的変数、それ以降の列に説明変数を格納したCSVファイルとして下さい。また、今回は回帰になるので文字列は含まないようにして下さい。
■出力ファイル
- モデル評価結果(model_evaluation.csv)
学習データにより構築したランダムフォレスト回帰モデルについて性能評価した結果を格納したファイルになります。今回は $r^2$ で評価を行なっています。
- 変数重要度(feature_importance.csv)
構築したランダムフォレスト回帰モデルから変数重要度を算出した結果を格納したファイルになります。今回は不純度の平均減少量(Mean Decrease in Impurity, MDI)から変数重要度を算出しています。これは各特徴量が決定木のノードで使われることで、どれだけ不純度が減少するかを測定した手法になります。
実装コードと解説
それでは今回実装したコードとその解説をしていきます。
実装したコードは以下の通りとなります。
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# CSVファイルの読み込み
file_path = 'your_file.csv' # ファイルパスを指定してください
data = pd.read_csv(file_path)
# 目的変数と説明変数の設定
X = data.iloc[:, 1:] # 説明変数
y = data.iloc[:, 0] # 目的変数
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 最適なmax_featuresの割合を見つける
best_max_features = None
best_oob_r2 = -float('inf')
for ratio in [i * 0.1 for i in range(11)]:
if ratio == 0:
continue # max_features = 0は意味がないのでスキップ
rf = RandomForestRegressor(n_estimators=300, max_features=ratio, oob_score=True, random_state=42)
rf.fit(X_train, y_train)
oob_r2 = rf.oob_score_
print(f"max_features ratio: {round(ratio,1)}, OOB R^2: {round(oob_r2,3)}")
if oob_r2 > best_oob_r2:
best_oob_r2 = oob_r2
best_max_features = ratio
print(f"Best max_features ratio: {round(best_max_features,1)}, Best OOB R^2: {round(best_oob_r2,3)}")
# 最適なmax_featuresの割合で最終モデルを訓練
rf_best = RandomForestRegressor(n_estimators=500, max_features=best_max_features, oob_score=True, random_state=42)
rf_best.fit(X_train, y_train)
# テストデータで予測
y_pred = rf_best.predict(X_test)
# モデルの評価
mse = round(mean_squared_error(y_test, y_pred),2)
r2 = round(r2_score(y_test, y_pred),2)
print(f"Mean Squared Error: {mse}")
print(f"R-squared: {r2}")
# 評価結果をCSVに保存
evaluation_results = pd.DataFrame({
'Metric': ['Mean Squared Error', 'R-squared'],
'Value': [mse, r2]
})
evaluation_results.to_csv('model_evaluation.csv', index=False)
# 特徴量の重要度の表示
importances = rf_best.feature_importances_
feature_names = X.columns
importance_df = pd.DataFrame({'Feature': feature_names, 'Importance': importances})
importance_df = importance_df.sort_values(by='Importance', ascending=False)
print(importance_df)
# 変数重要度をCSVに保存
importance_df.to_csv('feature_importance.csv', index=False)
上記のコードは大きく4つのフローに分かれています。
- データ前処理
- 使用する説明変数の数の最適化
- ランダムフォレスト回帰の実行と予測性能評価
- 変数重要度の計算
以降、順番に説明していきます。
データ前処理
まずはデータ前処理についてです。
データの前処理については以下のコードで実行しています。
# CSVファイルの読み込み
file_path = 'your_file.csv' # ファイルパスを指定してください
data = pd.read_csv(file_path)
# 目的変数と説明変数の設定
X = data.iloc[:, 1:] # 説明変数
y = data.iloc[:, 0] # 目的変数
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)ファイルパスを指定して、使用する学習データが格納されたCSVファイルを読み込みます。さらに目的変数と説明変数を列指定によって切り分けます。
最後に訓練データとテストデータに分割しています。ランダムフォレストではデータの標準化が不要なので、簡単な前処理のみとしています。
使用する説明変数の数の最適化
次に使用する説明変数の数の最適化についてです。
コード中の以下の部分で実行しています。
# 最適なmax_featuresの割合を見つける
best_max_features = None
best_oob_r2 = -float('inf')
for ratio in [i * 0.1 for i in range(11)]:
if ratio == 0:
continue # max_features = 0は意味がないのでスキップ
rf = RandomForestRegressor(n_estimators=300, max_features=ratio, oob_score=True, random_state=42)
rf.fit(X_train, y_train)
oob_r2 = rf.oob_score_
print(f"max_features ratio: {round(ratio,1)}, OOB R^2: {round(oob_r2,3)}")
if oob_r2 > best_oob_r2:
best_oob_r2 = oob_r2
best_max_features = ratio
print(f"Best max_features ratio: {round(best_max_features,1)}, Best OOB R^2: {round(best_oob_r2,3)}")
今回のランダムフォレスト回帰では各決定木にて全ての変数m個の内、いくつの変数を使用するかを最適化しています。
具体的な手法として、全ての変数に対して何割の変数を使用するかを $r^2$ 値で評価することで最適化しており、使用する変数の割合は0.1から1.0まで0.1刻みでグリッドサーチしています。また、 $r^2$ 値を計算する際はOOB( Out-Of-Bag)のデータを使用しています。
OOBとはサブデータを作成する際にサンプルは重複を許して選択されるのですが、その中で選択されなかったサンプルのことを指しています。
コードの説明としては、まず数値の初期化として、best_max_featuresはNone、best_oob_r2はマイナスの無限大として-float(‘inf’)を設定しています。
次に使用する変数の割合を0.1から1.0まで0.1刻みで性能を評価しています。この際、ランダムフォレストの木の数は300個を指定しています。
最終的に最も性能が良かった説明変数の割合とその $r^2$ 値を出力するようにしています。
ランダムフォレスト回帰の実行と性能評価
次に最も性能が良かった説明変数の割合においてランダムフォレスト回帰と予測性能評価を行なっています。
実行しているコードは以下の部分です。
# 最適なmax_featuresの割合で最終モデルを訓練
rf_best = RandomForestRegressor(n_estimators=500, max_features=best_max_features, oob_score=True, random_state=42)
rf_best.fit(X_train, y_train)
# テストデータで予測
y_pred = rf_best.predict(X_test)
# モデルの評価
mse = round(mean_squared_error(y_test, y_pred),2)
r2 = round(r2_score(y_test, y_pred),2)
print(f"Mean Squared Error: {mse}")
print(f"R-squared: {r2}")
# 評価結果をCSVに保存
evaluation_results = pd.DataFrame({
'Metric': ['Mean Squared Error', 'R-squared'],
'Value': [mse, r2]
})
evaluation_results.to_csv('model_evaluation.csv', index=False)まず、ランダムフォレスト回帰を実行しており、この際、決定木の数は500で設定されています。
次に、構築したモデルに対してテストデータで予測し、 $r^2$ 値とMSEを出力するようにしています。また、この際、$r^2$ 値とMSEはCSVファイルとしても出力されるようになっています。
変数重要度の計算
最後に変数重要度の計算についてです。
実行コードは以下の部分になります。
# 特徴量の重要度の表示
importances = rf_best.feature_importances_
feature_names = X.columns
importance_df = pd.DataFrame({'Feature': feature_names, 'Importance': importances})
importance_df = importance_df.sort_values(by='Importance', ascending=False)
print(importance_df)
# 変数重要度をCSVに保存
importance_df.to_csv('feature_importance.csv', index=False)
今回、変数の重要度については不純度の平均減少(Mean Decrease in Impurity, MDI)から算出しています。
コードの中ではrf_best.feature_importances_にて変数の重要度を取得しており、データフレームに格納し、CSVとして出力しています。
オススメの書籍
最後にランダムフォレストについてもっと知りたい方に向けてオススメの書籍をご紹介します。
以下に紹介する「Pythonで学ぶ実験計画法入門 ベイズ最適化によるデータ解析」では初心者にも非常にわかりやすいようにベイズ最適化をはじめとして様々な実験計画法について説明されています。
もちろん、ランダムフォレストについても書かれており、実際にGithubからPythonコードとデータセットを取得できるので、自分で実践しながらランダムフォレストについて勉強することができます。
また、ランダムフォレスト以外についても機械学習の手法が記載されているので、ご興味のある方はぜひ購入いただければと思います。

終わりに
以上がCSVを入力するだけでランダムフォレスト回帰を実行するコードの紹介と説明になります。ランダムフォレストは非常によく使われる解析の一つなので、少しでも参考になれば嬉しいです。よく使用する回帰手法についてはまたコードを作成してご紹介したいと思っています。