こんにちは!ぼりたそです。
今回は、機械学習における回帰モデルの評価指標について、初心者の方にもわかりやすく徹底的に解説していきます。
回帰分析を行ったあと、「このモデルって結局どれくらい良いの?」「MSEとかR²とか出てきたけど、どれを見ればいいの?」と疑問に思ったことはありませんか?
本記事では、回帰モデルでよく使われる指標(MSE, RMSE, MAE, R², Adjusted R²)について、以下のポイントでまとめています。
- 特徴と使い分けの早見表
- 数式と意味の解説
- Pythonでの実装例
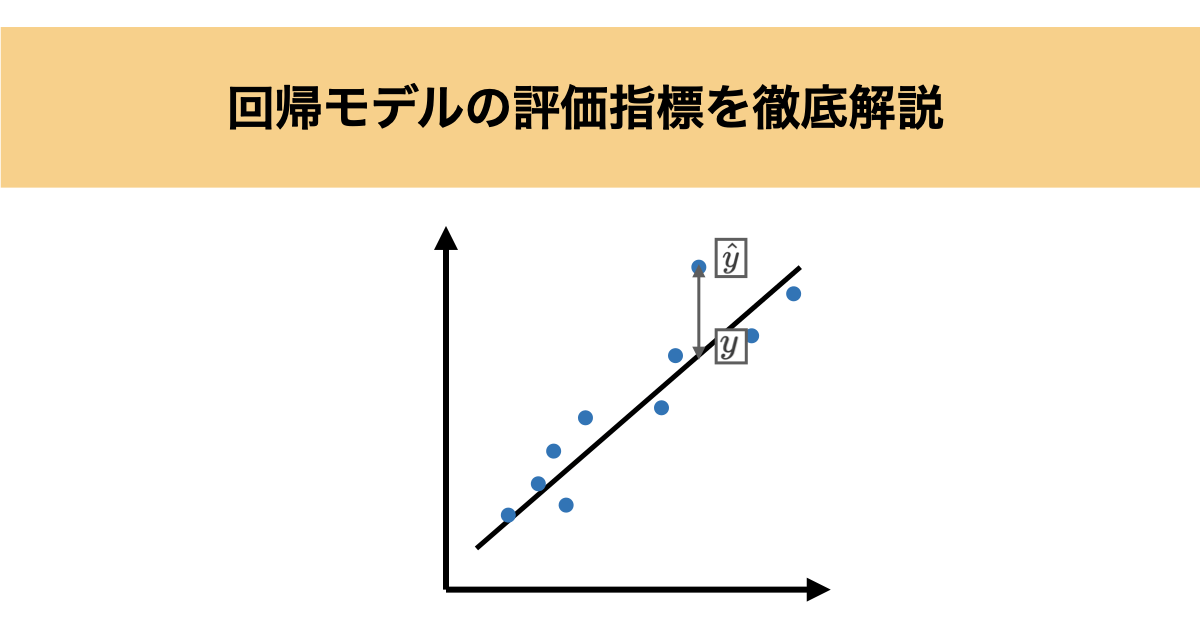
回帰モデルにおける「評価」とは?
回帰モデルでは、予測値( $\hat{y}$ )と実測値( $y$ )のズレを評価します。 このズレ(誤差)をどのように測るかによって、モデルの「精度」や「説明力」の見方が変わってきます。
そのため、適切な評価指標を選ぶことは、モデル選定や改善に欠かせない重要なステップです。

評価指標の特徴と使い分け早見表
以下の表では、回帰モデルの代表的な評価指標ごとに「どんな特徴があるのか」「どんな状況で使うのが適しているか」をざっくり把握できるようにまとめています。まずはこの表を見て、全体像をつかみましょう。
向いている場面を記載していますが、基本的には複数の評価指標を使うことをオススメします。一つの評価指標のみを使用すると一つの側面しか評価できず、モデル全体としての評価ができない可能性があるからです。
| 指標名 | 特徴 | 向いている場面 |
|---|---|---|
| MSE | 誤差を二乗して平均。外れ値を強調 | 精度を重視、学習時の損失関数に使用 |
| RMSE | MSEの平方根。単位が元のデータと同じで直感的 | ズレの大きさをわかりやすく示したいとき |
| MAE | 誤差の絶対値の平均。外れ値に強い | ノイズや外れ値の多いデータ |
| R² | モデルの説明力(ばらつきの再現度) | モデル全体の性能をざっくり確認したいとき |
| Adjusted R² | R²に特徴量数の調整を加えた指標 | 多変量回帰や特徴量選定時 |
各評価指標の詳しい解説
この章では、それぞれの評価指標の数式・意味・メリット・デメリットについて、初心者の方でも理解しやすいように丁寧に解説していきます。
MSE(Mean Squared Error)
$$
\mathrm{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i – \hat{y}_i)^2
$$
$n$ : データ数
MSEは、予測値と実測値の差を二乗して平均した指標です。二乗することで大きな誤差をより強く反映させる特徴があり、外れ値に対して敏感です。
特に、学習時の損失関数としても広く使われており、予測精度を重視する場面でよく用いられます。ただし、単位が元のデータの二乗になるため、直感的には捉えにくいかもしれません。
RMSE(Root Mean Squared Error)
$$
\mathrm{RMSE} = \sqrt{ \frac{1}{n} \sum_{i=1}^{n} (y_i – \hat{y}_i)^2 }
$$
$n$ : データ数
RMSEはMSEの平方根をとったものです。MSEと同様に誤差を二乗して扱うため外れ値に敏感ですが、平方根をとることで単位が元のデータと一致し、直感的に理解しやすいメリットがあります。
実務では、誤差の“実際の大きさ”を把握したいときに、RMSEの方がよく用いられます。
MAE(Mean Absolute Error)
$$\mathrm{MAE} = \frac{1}{n} \sum_{i=1}^{n} \left| y_i – \hat{y}_i \right|$$
$n$ : データ数
MAEは、予測値と実測値の絶対値の差の平均です。二乗ではなく絶対値を取ることで、外れ値の影響を抑えた評価が可能です。
ノイズが多いデータや外れ値が含まれる場合には、MSEやRMSEよりもMAEの方が適しています。誤差の大きさを平均的に把握したいときにも有効です。
R²(決定係数)
$$R^2 = 1 – \frac{ \sum_{i=1}^{n} (y_i – \hat{y_i})^2 }{ \sum_{i=1}^{n} (y_i – \bar{y})^2 }$$
$n$ : データ数
R²は、モデルが目的変数のばらつきをどれだけ説明できているかを示す指標です。値は1に近いほど良く、0に近いとモデルに説明力がないことを意味します。
ただし、特徴量を増やせば必ずR²は上がるため、多変量回帰では注意が必要です。全体のモデル性能をざっくり確認したいときに便利です。
Adjusted R²(修正済み決定係数)
$$
R^2_{\mathrm{adj}} = 1 – \left(1 – R^2\right) \cdot \frac{n – 1}{n – p – 1}
$$
$n$ : データ数
$p$ : 変数の数
Adjusted R²は、通常のR²に説明変数の数(自由度)に基づく調整を加えた指標です。
不要な特徴量を追加したことでR²が不自然に高くなる問題を補正してくれるため、特に多変量回帰モデルにおいて信頼性の高い評価が可能になります。特徴量選択や過学習のチェックにも役立つ指標です。
Pythonで実装してみよう
ここでは、実際にPythonを使って評価指標を計算する例を紹介します。
今回は、以下の2つのケースに分けて、非線形な関係をもつ回帰問題をランダムフォレスト回帰で10-Fold交差検証(CV)により評価してみます。
- Case1: 特徴量10個、データ数500個、外れ値なし
- Case2: 特徴量10個、データ数500個、外れ値1%
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.model_selection import KFold
# データ生成関数(非線形 + 外れ値付き)
def generate_nonlinear_data(n_samples=500, n_features=10, outlier_ratio=0.01, seed=42):
np.random.seed(seed)
X = np.random.randn(n_samples, n_features)
y = (
np.sin(X[:, 0]) + X[:, 1]**2 + np.log(np.abs(X[:, 2]) + 1)
+ np.exp(-X[:, 3]) + X[:, 4]*X[:, 5] + X[:, 6]**3
+ np.tanh(X[:, 7]) + np.abs(X[:, 8])
+ X[:, 9]
+np.random.normal(0, 0.5, size=n_samples)
)
# 外れ値の追加
n_outliers = int(n_samples * outlier_ratio)
y[:n_outliers] += np.random.normal(0, 30, size=n_outliers)
return X, y
# 評価関数
def evaluate_model_cv(X, y, n_splits=10):
kf = KFold(n_splits=n_splits, shuffle=True, random_state=42)
metrics = {'MSE': [], 'RMSE': [], 'MAE': [], 'R2': [], 'Adjusted R2': []}
for train_idx, test_idx in kf.split(X):
X_train, X_test = X[train_idx], X[test_idx]
y_train, y_test = y[train_idx], y[test_idx]
model = RandomForestRegressor(
n_estimators=500,
max_depth=30,
min_samples_leaf=3,
random_state=42
)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
n, p = X_test.shape
r2 = r2_score(y_test, y_pred)
metrics['MSE'].append(mean_squared_error(y_test, y_pred))
metrics['RMSE'].append(mean_squared_error(y_test, y_pred, squared=False))
metrics['MAE'].append(mean_absolute_error(y_test, y_pred))
metrics['R2'].append(r2.round(2))
metrics['Adjusted R2'].append(1 - (1 - r2) * (n - 1) / (n - p - 1))
return {k: round(np.mean(v), 2) for k, v in metrics.items()}
# Case 1
X1, y1 = generate_nonlinear_data(n_samples=500, n_features=10, outlier_ratio=0.00)
print("Case 1 Results:")
print(evaluate_model_cv(X1, y1))
# Case 2
X2, y2 = generate_nonlinear_data(n_samples=500, n_features=10, outlier_ratio=0.01)
print("Case 2 Results:")
print(evaluate_model_cv(X2, y2))| ケース | MSE | RMSE | MAE | R² | Adjusted R² |
|---|---|---|---|---|---|
| Case 1 (外れ値無し) | 5.72 | 2.30 | 1.51 | 0.77 | 0.71 |
| Case 2 (外れ値1%) | 11.39 | 3.01 | 1.77 | 0.68 | 0.60 |
以下に実行結果について外れ値の影響がどのように評価指標に作用したかをまとめます。
- MSEやRMSEが大きく上昇
→ 外れ値(1%)の影響を受けて、誤差が増加しています。MSEやRMSEは外れ値に敏感であることがよくわかります。
- MAEの変化は緩やか
→ 外れ値があっても比較的安定。MAEは外れ値に強く安定的であることを示しています。
- R²とAdjusted R²の低下
→ 外れ値の追加によりモデルの説明力が下がり、R²が0.77から0.68へ、Adjusted R²も0.71から0.60へと減少しました。- R²は単に説明力を示す指標ですが、Adjusted R²は特徴量数を考慮して下方補正されています。
- Adjusted R²の低下幅がR²よりも大きい場合、過剰な特徴量やモデルの過学習を疑うきっかけになります。
この比較から、外れ値の有無によって評価指標が大きく変化すること、そして複数の指標を組み合わせて総合的に判断する重要性がよくわかります。
学習ステップをさらに進めたい方へ
回帰モデルの評価指標(MSE/MAE/RMSE/R²/Adjusted R²)を正しく使い分けるには、アルゴリズムの中身を理解していることが近道です。そこでおすすめなのが
『図解即戦力 機械学習&ディープラーニングのしくみと技術がこれ一冊でしっかりわかる教科書』です。

この本を通じて、機械学習を“便利な道具”として使うだけでなく、仕組みを説明しながら使える力が身につきます。ブラックボックス化を避けられるため、「なぜ誤差がこう効くのか」「R²が下がる理由は何か」といった評価指標の解釈がブレなくなり、実務での応用力が大きく向上します。
「機械学習の仕組みを理解しながら自分で実装できるようになりたい」という方には最適の一冊。使い方だけでなく仕組みを説明できる力が身につくので、現場での応用力がぐっと高まります。
一方で「Pythonはこれから…」「数式で挫折したことがある…」という方もいらっしゃるかと思います。
そんな初学者の方でもpythonで機械学習を実装できるようになるためのロードマップとオススメの教材について以下の記事にまとめていますので、興味のある方はご覧になって下さい。

終わりに
回帰モデルの精度を正しく評価するには、MSEやMAE、R²など複数の指標を使い分けることが重要です。本記事では、それぞれの評価指標の特徴と使いどころをわかりやすく整理し、Pythonでの実装例も紹介しました。目的やデータの性質に応じて、適切な指標を選びましょう!

