こんにちは!ぼりたそです!
今回は次元削減法であるt-SNEについて初学者の方でもわかりやすいように解説していきます。
この記事は以下のポイントを説明しています。
- t-SNEとは?
- なぜt-SNEが必要なのか?
- t-SNEのアルゴリズム
- Pythonで実装
また、以前に他の次元削減法としてPCA(主成分分析)、UMAPに関する記事もまとめていますので興味のある方はご覧いただければと思います。

それでは順番に解説していきます。
t-SNEとは?
t-SNE(t-Distributed Stochastic Neighbor Embedding)は次元削減法の一つで、大きな特徴として次元圧縮した際に似ているデータ同士が近くに配置されるように可視化できる点が挙げられます。これにより、高次元データでは可視化できなかったクラスタの構造が見やすくなります。
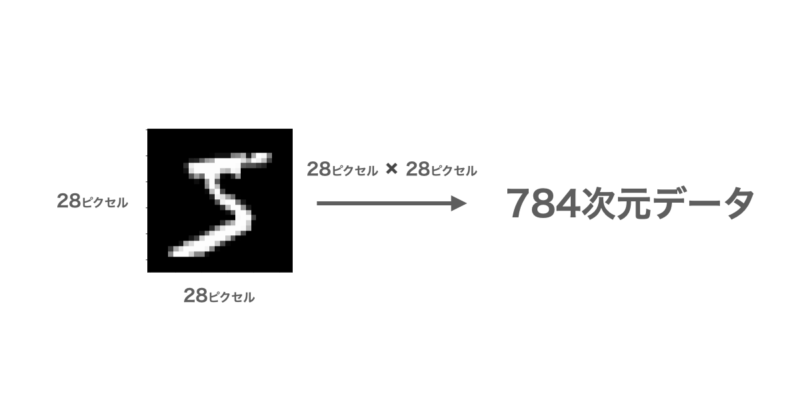
例えば、手書き数字データ(MNIST)は下図のように28×28ビットの合計784ビットとして表され、各ビットは白から黒までの濃淡を表す0~255の数値が格納されています。
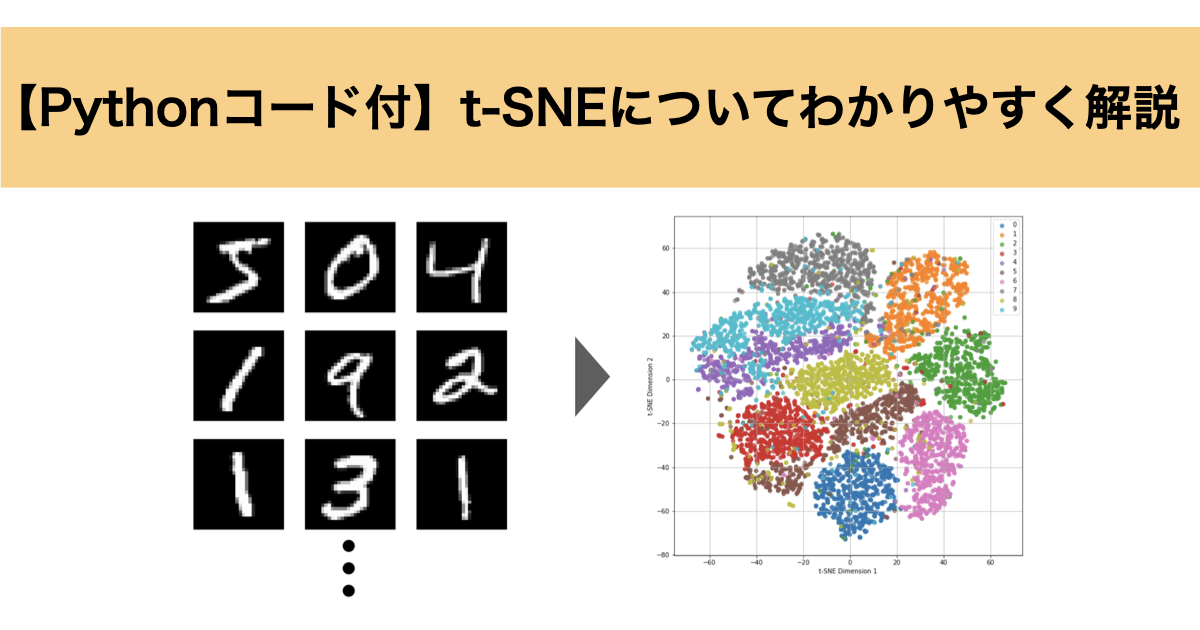
このMNISTが0~9の数字について10000個ある場合、t-SNEを実行すると次のように二次元グラフでそれぞれの数字ごとにクラスターとして可視化することができました。
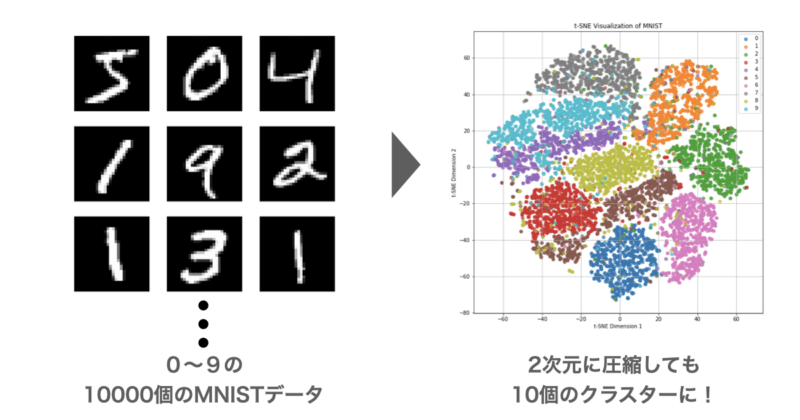
このようにt-SNEでは高次元の類似性を維持しつつ低次元において可視化してくれる次元削減法になります。
なぜt-SNEが必要なのか?
次に次元削減法については手法がいくつかありますが、なぜt-SNEが必要なのかについて説明していきます。
ここでは次元削減法でよく使用されるPCAやUMAPと比較してみます。
下の表に簡単ですが各手法の強み、弱み、使用場面についてまとめてみました。
| 手法 | 強み | 弱み | 使用場面 |
|---|---|---|---|
| PCA | ・線形情報の保持 ・計算が速い | ・非線形情報が捉えられない ・クラスタが重なりがち | ・前処理 ・特徴量選択 ・全体構造の把握 |
| t-SNE | ・局所構造の保持 ・クラスタの明確な分離 | ・計算が遅い ・大域構造が歪む | ・クラスタの可視化 ・類似データの探索 |
| UMAP | ・局所/大域構造のバランス ・高速な計算 | ・ハイパーパラメータ調整が難しい | ・大規模データの可視化 ・クラスタリングの補助 |
結論としてはどの手法も強みと弱みがあり使い方次第なのですが、t-SNEに注目すると次元削減後も局所構造を保持でき、クラスターの明確な分離ができる点が強みになっています。
PCAでは線形情報の保持や計算が速いという強みがありますが、非線形情報が捉えられずクラスターが重なりがちである弱みがあり、この点においてはt-SNEの方が優位な特徴と言えます。
また、UMAPは次元削減後も局所/大域構造のバランスがよく、計算も速いですがハイパーパラメータの調整が難しいという弱みがあり、t-SNEは比較的ハイパーパラメータの調整も簡単であり優位な点と言えます。
以上からt-SNEはPCAやUMAPと比較して優れる点もあり、具体的な用途としてクラスタ構造の可視化や類似データの探索をしたい場合に必要になる手法と言えます。
一方でt-SNEは計算が遅く、次元削減後の大域構造が歪む傾向があるので使用目的に応じてPCAやUMAPなどの手法を選択することが好ましいです。
t-SNEのアルゴリズム
次にt-SNEのアルゴリズムについて説明していきます。
t-SNEは高次元空間 でのデータ点の距離感 を低次元空間 にそのまま保つ。つまり、「近い点は近くに、遠い点は遠くに」 を目指すことを目的としています。
これを実現するアルゴリズムとして具体的な手順で処理しています。
- 高次元空間におけるデータの近さを定義
- 低次元空間におけるデータの近さを定義
- コスト関数を定義
- コスト関数の最小化
それぞれ順に説明していきます。
高次元空間におけるデータの近さを定義
まずは高次元空間におけるデータの近さを定義していきます。
データ点 $x_1, x_2, …, x_n$を考えるとき、それぞれのデータ点がガウス分布に従うと仮定します。
データをガウス分布として扱っているのは近い点の確率が高く、遠い点の確率が急激に小さくなる特性を持ち、局所的な構造 をうまく捉えるのに適しているからという理由があります。
このとき、データ点 $x_i$ と $x_j$の距離は以下の条件付き確率分布として表します。
$$p_{j|i} = \frac{\exp\left(-\frac{| x_i – x_j |^2}{2 \sigma_i^2}\right)}{\sum_{k \neq i} \exp\left(-\frac{| x_i – x_k |^2}{2 \sigma_i^2}\right)}$$
$sigma_i$ はスケールパラメータ(バンド幅) で、パープレキシティによって値が調整されます。
パープレキシティはここでは詳しく説明しませんが、簡単に言うと「1つの点が影響を受ける周りの点の数」 を決めるパラメータで、パープレキシティ が 小さいと小さなクラスターが密集し、大きいとクラスターが大きくなる傾向があります。
また、上の条件付き確率を対称化するために以下のように $p_{j|i}$ と $p_{i|j}$ の平均 を取って、対称な確率 $P_{ij}$ を定義し、これを高次元空間におけるデータの近さとします。
$$P_{ij} = \frac{p_{j|i} + p_{i|j}}{2N}$$
このとき、対称化するのは点 $x_i$ から見た $x_j$ の近さと、点 $x_j$ から見た $x_i$ の近さを平均化したいからです。
$p_{i|j}$ と $p_{j|i}$ は一般に異なっており、
例えば、点 $x_i$ の周りにたくさんの点があり、点$x_j$の周りにはあまり点がない場合、$p_{j|i}$ は小さくなるが$p_{i|j}$ は大きくなってしまいます。そうなると近さの扱いが煩雑になるため対称化を行なっています。
低次元空間におけるデータの近さを定義
次に低次元空間におけるデータの近さを定義していきます。
低次元に変換したデータ点 $y_1, y_2, …, y_n$を考えるとき、それぞれのデータ点がt分布に従うと仮定します。
このとき、データ点 $y_i$ と $y_j$の距離は以下の確率分布$Q_{ij}$として表し、これを低次元におけるデータの近さとして定義します。
$$Q_{ij} = \frac{\left( 1 + | y_i – y_j |^2 \right)^{-1}}{\sum_{k \neq l} \left( 1 + | y_k – y_l |^2 \right)^{-1}}$$
ここで、データをt 分布 (自由度1のt分布)として扱うのは、t分布は裾が広く遠い点までその確率を考慮できる特性を持つため、遠い点の影響を抑えクラスタ間をはっきりと分けられるという理由があります。
コスト関数を定義
次に損失関数を定義していきます。
高次元の確率 $P_{ij}$ と 低次元の確率 $Q_{ij}$ の差異をKLダイバージェンスを使用したコスト関数 $C$ として定義します。
KLダイバージェンスは、2つの確率分布の間の違いを測る指標です。簡単に言うと、ある確率分布 $P$ が、もう一方の確率分布 $Q$ にどれだけ「似ていないか」を表す指標です。
$$C = \sum_{i \neq j} P_{ij} \log \frac{P_{ij}}{Q_{ij}}$$
コスト関数の最小化
最後に定義したコスト関数 $C$ について最小化するように $y_i$ を更新していきます。
コスト関数 $C4 を最小化するためには勾配降下法 を使用します。
勾配降下法は、関数の最小値を見つけるための手法です。具体的には、関数の勾配(傾き)を利用して、関数の値が減少する方向にパラメータを更新していきます。
山の頂上から谷底へと降りていくプロセスを想像するとわかりやすいのですが、山の傾きを調べて最も急な降り方向に進む、これを何度も繰り返すことで、最終的に谷底(関数の最小値)に到達することを目指します。
勾配の計算:
$$\frac{\partial C}{\partial y_i} = 4 \sum_{j \neq i} \left( P_{ij} – Q_{ij} \right) \left( y_i – y_j \right) \left( 1 + | y_i – y_j |^2 \right)^{-1}$$
計算した勾配から以下の式に従って $y_i$ を更新していきます。
$$y_i \leftarrow y_i – \eta \frac{\partial C}{\partial y_i}$$
このとき、$P_{ij} > Q_{ij}$ のとき、 $y_i$ を近づけるように更新し、$P_{ij} < Q_{ij}$ のとき、 $y_i$ を遠ざけるように更新します。
また、$\eta$ は学習率であり勾配に対してどれだけ進むかを表しています。大きすぎると最小値を過ぎてしまい解が収束せず、小さすぎると最小化まで膨大な時間がかかってしまいます。
以上のアルゴリズムから高次元空間 でのデータ点の距離感 を低次元空間 にそのまま保つような次元削減を行うことができます。
Pythonで実装
それでは実際にPythonを使用してt-SNEを実行してみましょう。
今回は冒頭で紹介した0〜9の手書き数字(MNIS)のデータ10000件をt-SNEにより二次元グラフに落とし込みます。
実行したコードは以下の通りです。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml
from sklearn.manifold import TSNE
from sklearn.preprocessing import StandardScaler
# MNIST データセットのダウンロード
mnist = fetch_openml('mnist_784', version=1, as_frame=False)
X = mnist.data
y = mnist.target.astype(int)
# データの標準化
# scaler = StandardScaler()
# X_scaled = scaler.fit_transform(X)
# 計算量削減のため、ランダムに 10000 件を抽出
np.random.seed(42)
indices = np.random.choice(X.shape[0], 10000, replace=False)
X_subset = X[indices]
y_subset = y[indices]
# t-SNE モデルの作成と適用
tsne = TSNE(n_components=2, perplexity=10, learning_rate=50, random_state=42)
X_tsne = tsne.fit_transform(X_subset)
# プロットの設定
plt.figure(figsize=(10, 10))
# 各クラス(0〜9)のプロット
for i in range(10):
# 各ラベルのデータを取得
indices = y_subset == i
plt.scatter(X_tsne[indices, 0], X_tsne[indices, 1], label=str(i), alpha=0.7)
# プロットの装飾
plt.legend()
plt.title("t-SNE Visualization of MNIST")
plt.xlabel("t-SNE Dimension 1")
plt.ylabel("t-SNE Dimension 2")
plt.grid(True)
plt.show()実行結果は以下のグラフのようになっており、元々784次元だったデータを二次元に落とし込んでも0~9の数字ごとにきちんと10個のクラスターに分かれていることがわかります。
また、似たような数字の形をしている「4」、「7」、「9」や「3」、「8」、「5」はクラスター同士が近い傾向が読み取れます。
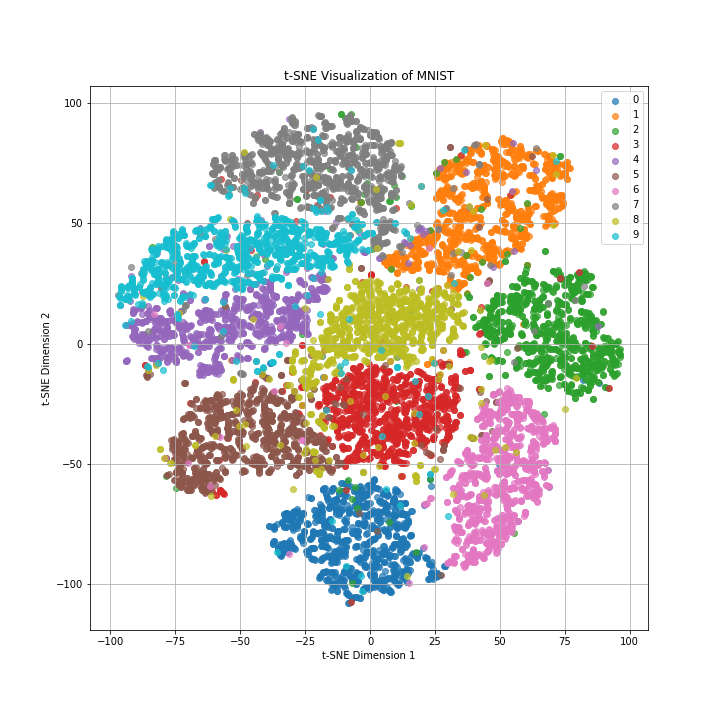
以上がPythonによるt-SNEの実行方法になります。
終わりに
以上がt-SNEに関する解説になります。次元削減を行なってもきちんとデータ間の距離情報が維持されるのは非常に便利だと感じました。次元削減の手法もt-SNEの他にPCAやUMAPなど色々あるので、今後ご紹介していきたいと思います。